一文带你了解基于视觉的机器人抓取自学习( 二 )
为了解决这种识别问题 , 需要一种感知系统:该系统能从非结构化图像数据中提取有意义的物体概念 , 并能以无监督的方式学习物体的视觉感知 。 该研究在数据收集的过程中 , 利用机器人可以操纵物体移动的优势 , 提供数据所需的变化因素 。 通过对物体进行抓取 , 可以获得1)抓取前的场景图像;2)抓取后的场景图像;3)抓握物体本身的孤立视图 。
研究人员提出了一个从图像中提取“物体集合”的嵌入函数 , 该函数满足以下减法关系: 文章插图
文章插图
文中使用了全卷积架构和简单的度量学习算法来实现这种等式关系 , 特征图中嵌入抓取前的场景图像和抓取后的场景图像 , 并将其平均池化后保存到向量中 , 而“抓取前”和“抓取后”向量的差表示一组物体 。 该向量和对应的被抓取物体的向量表示之间的等价约束是通过N-Pairs目标函数实现的 。 通过N-Pairs目标函数实现该向量和对应的被抓取物体的向量之间的等价约束关系 。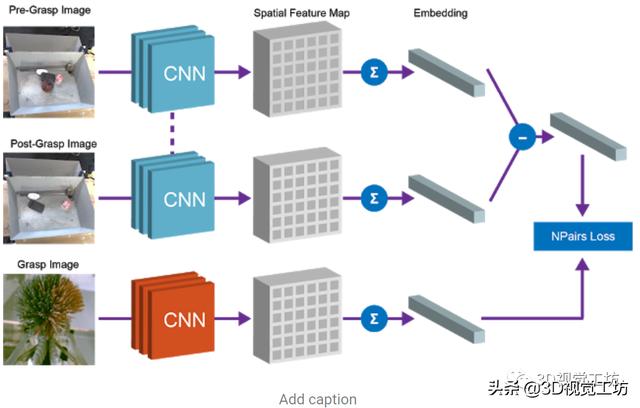 文章插图
文章插图
训练过后 , 模型中会出现两个有用的属性 。
1)物体相似度
第一个属性是余弦距离 , 利用向量间的余弦距离对物体进行比较 , 并确定是否相同 。 这个属性可以用于实现强化学习的奖励函数 , 并允许机器人在没有人工提供的标签的情况下学习实例抓取 。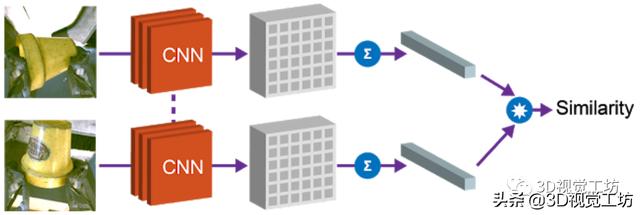 文章插图
文章插图
2)目标物体本地化
第二个属性是 , 可以组合场景空间映射和物体嵌入来本地化图像空间中的“查询对象” 。 将空间场景的特征图和查询对象的向量相乘 , 以找到两者之间“匹配”的所有像素 。 例如下图中的场景 , 模型可以检测出场景中的多个相应的色块 , 通过点乘得到的“热图” , 可用于规划机器人接近目标物体的方法 。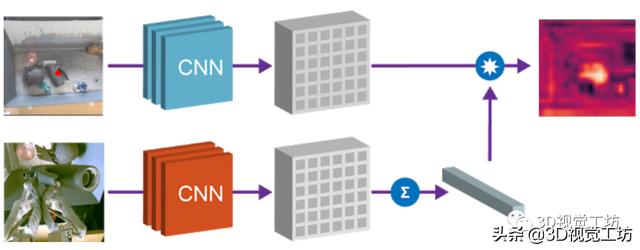 文章插图
文章插图
该项目展示了机器人抓取技能如何生成用于学习以物体为中心的表示的数据 , 并使用表示学习来实现更复杂的技能 , 例如实例抓取 , 与此同时保留自主抓取系统中的自监督学习属性 。
2、基于视觉和语音信息的机器人抓取
Improving Grounded Natural Language Understanding through Human-Robot Dialog
【摘要】机器人自然语言理解会需要大量特定性领域和平台的工程量 。 例如 , 移动机器人在特定环境中接收操纵者的命令拾取放置物品 , 人类可以指定语言为某类命令 , 并将概念词与物体对象的属性进行关联 , 例如红色这样的概念词 。 减轻类似工作量的方法是使环境中的机器人能够动态适应 , 不断学习新的语言构造和感知概念等 。 在这项工作中 , 研究人员提出了一种端到端的方法 , 用于将自然语言命令翻译为离散的机器人动作 , 并使用对话框共同明确和改善语义和基础概念 。 研究在Amazon Mechanical Turk的虚拟设置上对该目标对象进行训练和评估 , 并将该智能体转移到现实世界中的物理机器人平台上 , 进行展示 。
随着机器人在家庭、工厂和医院等环境中变得无处不在 , 人类对有效的人机交互的需求也在不断增长 。 上述各类场景中会包含特定的词汇和行为启示 , 例如 , 打开厨房的灯;把托盘往北移6英尺;如果病人的情况有变化 , 就通知我 。 因此 , 预编程机器人的语言理解会需要昂贵的特定性领域和平台的工程 。 在本文中 , 研究人员提出并评估了一种机器人智能体 , 它可以通过与人类对话的方式扩展一个初始状态下资源较少、依靠手工编程的语言理解管道 , 从而与人类伙伴更好地达成共识 。
研究人员结合了通过对话的信号进行更好的语义解析(以前不使用物体的感官表征)和主动学习方法来获取这些概念(以前仅限于对象识别任务) 。 因此,文中的系统能够执行自然语言命令 , 例如将一个能发出叮叮当当响声的容器从会议室的休息室移到Bob的办公室 , 其中包含组成语言(例如 , 语义分析器理解的会议室休息室以及将由其识别的对象的物理性质 , 如能发出叮叮当当响声的容器) 。 系统仅用少量的用于语义解析的自然语言数据进行初始化 , 没有将概念词与物理对象绑定的初始标签 , 而是需要通过人机对话学习解析和接地 。
本文的贡献主要是:1)提出了一种对话策略 , 仅利用少量初始领域内的训练数据来提高语言理解;2)利用对话问题在现场实时获取感知认识 , 而不是仅从预先标记的数据或过去的交互过程中获取;3)在一个完整的物理机器人平台上部署对话智能体 。
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 双行合一|关于Word我们要了解的知识(12)
- S7|vivo S7的6400万有多强?带你感受“神奇动物在哪里”
- 模式|刚了解到无货源电商模式,淘宝好还是抖音小店好?
- 微信|微信转账点收款就能收到钱了?这个“秘密”要了解,很多人上当了
- 工地|“智慧工地”是什么?记者带你全方位了解
- 这些错误,程序员经常会犯,你了解过吗?
- 现场|逛展看未来丨展会现场还能这么玩?带你解锁萌娃的逛展“姿势”
- 快速概览 + 详细了解N:N聚类算法是如何应用的
- 微服务如何保证不会出现连锁反应?Go 实现的断路器了解下