一文带你了解基于视觉的机器人抓取自学习( 三 )
研究人员在Mechanical Turk上评估智能体的学习能力和可用性 , 要求用户通过对话指挥智能体去完成三个任务:导航(由厨房去休息室) , 传递(将红色的罐子拿给Bob),和搬运(将一个空瓶子从厨房休息室转移到爱丽丝的办公室) 。 研究发现 , 根据之前对话中提取的信息对智能体进行训练后 , 它的评价指标会更好 。 然后 , 研究人员将经过训练的智能体转移到物理机器人上 , 并在人机对话中演示它的持续学习过程 。
该会话智能体主要通过视觉信息和自然语言结合完成请求 。 整体主要包括以下几个部分 。 1)语义解析器:智能体通过获取的单词序列推断任务的语义表示 , 使用组合类别语法(CCG)形式来进行解析 。 2)语言接地 , 根据不同的外部环境 , 相同的语义也可能会以不同的方式接地 。 例如 , 厨房旁边的办公室指的是一个物理位置 , 但这个位置取决于建筑 。 3)对话框 , 人机之间的对话常常从人类用户开始 , 指示智能体完成某项任务 , 智能体会对未观察到的真实任务进行建模 , 并使用来自用户的语言信号推断该任务 。 该命令由语义解析和基础组件处理 , 以获得成对的符号和置信状态值 。 置信状态值通过语义解析(例如 , “在北边的办公室的豆荚”中的介词歧义;豆荚还是办公室向北)和语言理解(例如 , 嘈杂的概念模型)步骤对不确定性进行建模 。 4)从对话中学习:该智能体通过在完成的对话中引入训练数据来改进其语义解析器 , 智能体能够将用户的初始命令与确认的动作进行匹配 , 从会话中学习语义 。 同时 , 采用主动学习的方式 , 从向用户提出的问题中快速扩展感知概念模型 , 然后在各个用户之间汇总扩展 , 并且可以将学习到的概念应用于远程测试对象 , 有助于获取新概念 。
会话智能体的组成如下图所示 , 左侧是将用户的命令进行语义解析 , 中间为利用已有的地图和概念模型等信息对指令进行接地 , 右侧是利用对话改进完善智能体的认知模型 。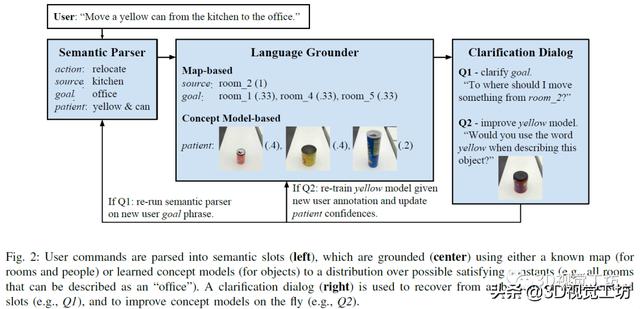 文章插图
文章插图
实验中指定的任务包含:根据用户指示完成到达指定地点 , 将物品递送给某人 , 将物品从指定地点移动到目的地 。 下图为受过训练的智能体采用动态学习的方式实现指定的目标 。 文章插图
文章插图 文章插图
文章插图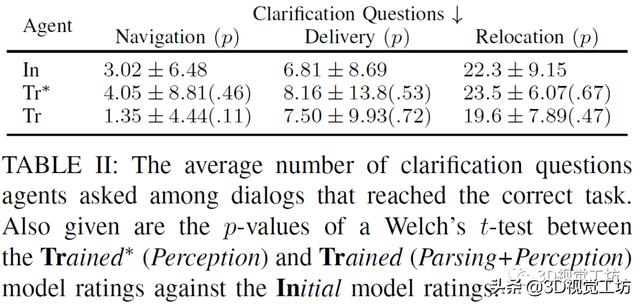 文章插图
文章插图
上表比较初始智能体 , 受过训练(仅感知训练)智能体 , 受过训练(解析训练和感知训练)的智能体三者的实验情况 , 衡量的标准是在满足正确的任务规范之前 , 需要进行的询问的问题的个数 , 实验显示受过训练(仅感知训练)智能体表现较差 , 可能是由于对话中的许多形容词和名词的属性没有及时更新 。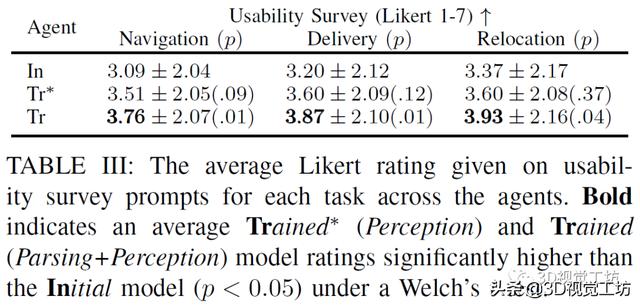 文章插图
文章插图
上表比较初始智能体 , 受过训练(仅感知训练)智能体 , 受过训练(解析训练和感知训练)的智能体三者的实验情况 , 衡量的标准是用户对智能体表现的定性的评价 , 主要包括:我将使用这样的机器人来帮助导航到一栋新楼;我将会用这样的机器人为自己或其他人拿取东西;我将会用这样的机器人来将物品从一个地方移到另一个地方 。 实验显示受过训练(解析和感知)的智能体的表现最好 。
该研究提出了一种机器人智能体 , 其可以利用与人类的对话来扩展自定义的小型化的语言理解资源 , 利用这些资源既可以将自然语言命令翻译为抽象的语义形式 , 又可以将物理对象的抽象属性接地 。 在这项工作中 , 机器人可以执行的动作可以分解为离散语义角色的元组 , 但是通常 , 他们需要推理更多的连续动作空间 , 并获取新的、与人类对话中看不见的行为和知识 。 该研究中的智能体可以从人机对话中学习知识 , 甚至可以处理复杂的形容词和名词之间的依赖和上下文关系 。
3、基于视觉和触觉信息的机器人抓取
Connecting Touch and Vision via Cross-Modal Prediction
【摘要】人类使用视觉、听觉和触觉等多种模式的感觉输入来感知世界 。 在这项工作中研究了视觉和触觉之间的交叉模式连接 。 跨模态建模任务的主要挑战在于两者之间在比例上存在显着差异:虽然我们的眼睛一次性就可以感知到整个视觉场景 , 但人类在任何给定时刻只能触碰感觉到物体的一个小部分 。 为了连接视觉和触觉 , 文中合成来自视觉输入的合理的触觉信号 , 以及想象我们如何与以触觉数据作为输入的对象进行交互 。 为了实现该目标 , 研究人员首先为机器人配备了视觉和触觉传感器 , 并收集了相应视觉和触觉图像序列的大规模数据集 。 为了缩小规模差距 , 研究中提出了一个新的条件对抗模型 , 该模型结合了触摸的规模和位置信息 。 人类的感知研究表明 , 本文中的模型可以从触觉数据中产生逼真的视觉图像 , 反之亦然 。 最后 , 展示了有关不同系统设计的定性和定量实验结果 , 以及可视化了模型的学习表示 。
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 双行合一|关于Word我们要了解的知识(12)
- S7|vivo S7的6400万有多强?带你感受“神奇动物在哪里”
- 模式|刚了解到无货源电商模式,淘宝好还是抖音小店好?
- 微信|微信转账点收款就能收到钱了?这个“秘密”要了解,很多人上当了
- 工地|“智慧工地”是什么?记者带你全方位了解
- 这些错误,程序员经常会犯,你了解过吗?
- 现场|逛展看未来丨展会现场还能这么玩?带你解锁萌娃的逛展“姿势”
- 快速概览 + 详细了解N:N聚类算法是如何应用的
- 微服务如何保证不会出现连锁反应?Go 实现的断路器了解下